Generations in America
Inspired by
Jason Timm’s post on Seven Generations of America
Kyle Walker’s Analyzing US Census Data
The
tidymodelsMulti-scale model assessment with spatialsample vignette by Mike Mahoney
Let’s have a look at the composition of American generations with Pew Research definitions and US Census data. By the end of this post, we should have a perspective on a few tools for exploring the changing demographics of America. This document was authored in RStudio in a qmd Quarto file using the R language and several open source packages, and is publicly available here.
Four of America’s seven living generations are more or less complete and
only getting smaller: Greatest, Silent, Boomers, and Gen X. The
generation comprised of Millenials is complete as well, in that it has
been delineated chronologically; however, the group continues to grow
via immigration.
| rank | gen | range |
|---|---|---|
| 1 | Greatest | < 1927 |
| 2 | Silent | 1928-1945 |
| 3 | Boomers | 1946-1964 |
| 4 | Gen X | 1965-1980 |
| 5 | Millennial | 1981-1996 |
| 6 | Gen Z | 1997-2012 |
| 7 | Post-Z | > 2012 |
| a https://www.pewresearch.org/fact-tank/2019/01/17/where-millennials-end-and-generation-z-begins/ |
While Gen Z has been tentatively stamped chronologically by the folks
at Pew Research, only about half have entered the work force. And though
we include them here, the Post-Z generation is mostly but a twinkle in
someones eye; half of the group has yet to be born.
Monthly US population estimates
The Monthly Postcensal Resident Population plus Armed Forces Overseas, December 2021 is made available by the US Census here. The census has transitioned to a new online interface, and this particular file is built off of some of their projections.
A more detailed description of the population estimates can be found here. Note: Race categories reflect non-Hispanic populations.
The following table details a random sample of the data set – with Pew Research defined generations & estimated year-of-birth.
| gen | range | race1 | yob | AGE | pop |
|---|---|---|---|---|---|
| Gen X | 1965-1980 | Asian | 1975 | 46 | 290698 |
| Post-Z | > 2012 | Native Hawaiian | 2013 | 8 | 8746 |
| Silent | 1928-1945 | Asian | 1938 | 83 | 58785 |
| Gen X | 1965-1980 | American Indian | 1970 | 51 | 29663 |
| Silent | 1928-1945 | Black | 1928 | 93 | 25214 |
| Millennial | 1981-1996 | American Indian | 1995 | 26 | 36466 |
| Post-Z | > 2012 | Black | 2020 | 1 | 520807 |
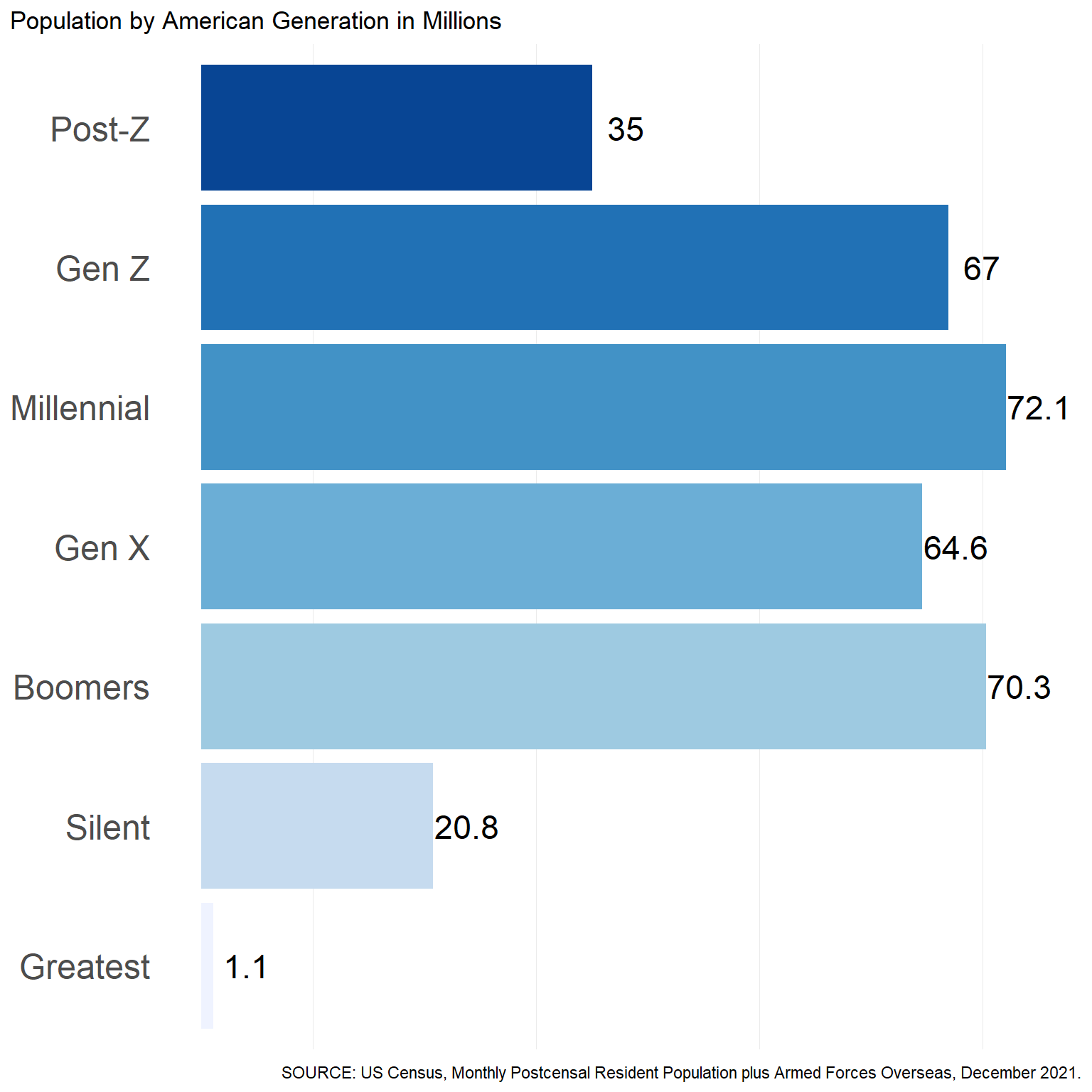
Compositions of American Generations
The figure below summarizes the US population by generation. These numbers will vary some depending on the data source.
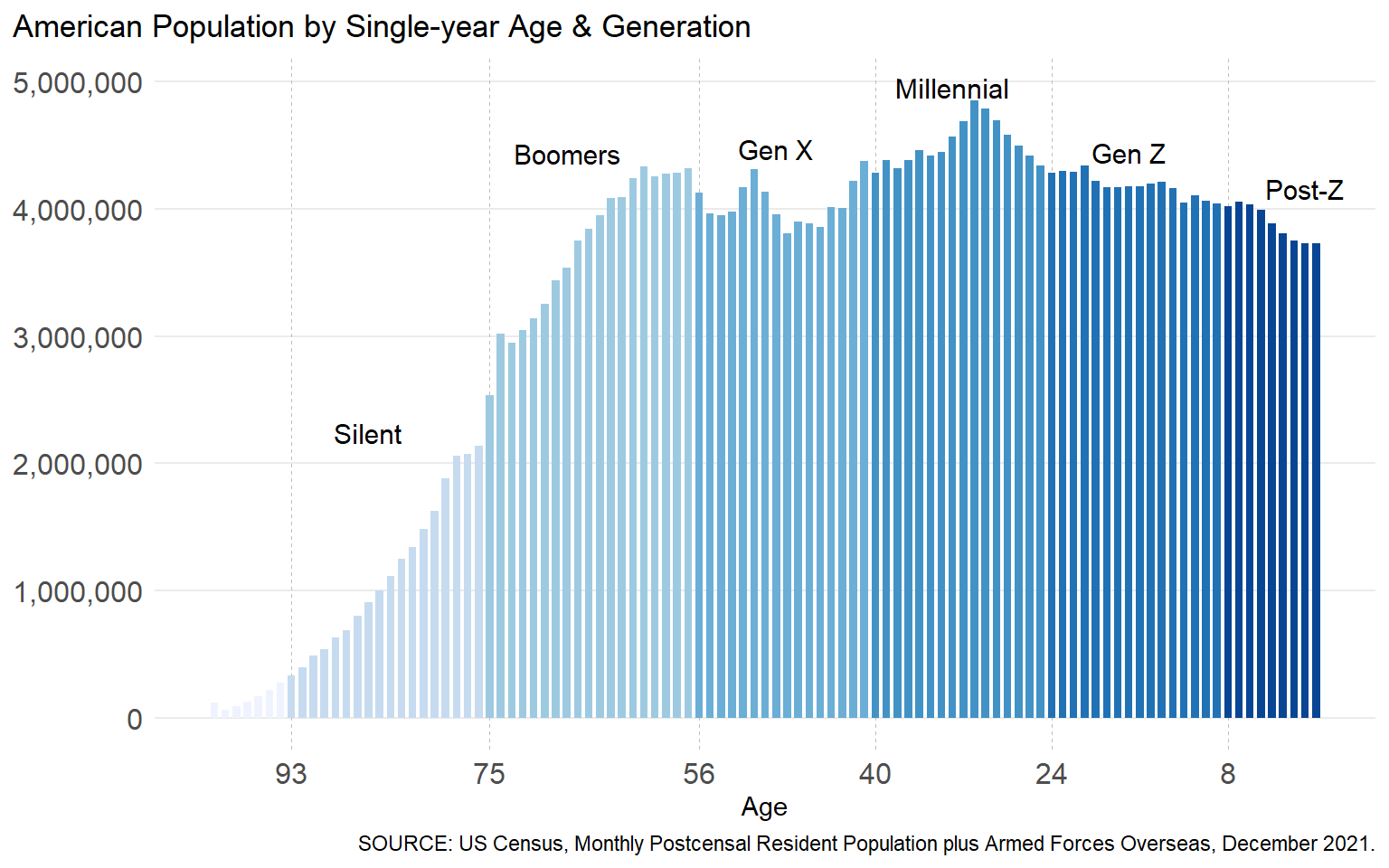
The figure below illustrates the US population by single year of age, ranging from the population aged less than a year to the population over 100. Generation membership per single year of age is specified by color.
Next, let’s cross the single year of age counts presented above by race & ethnicity.
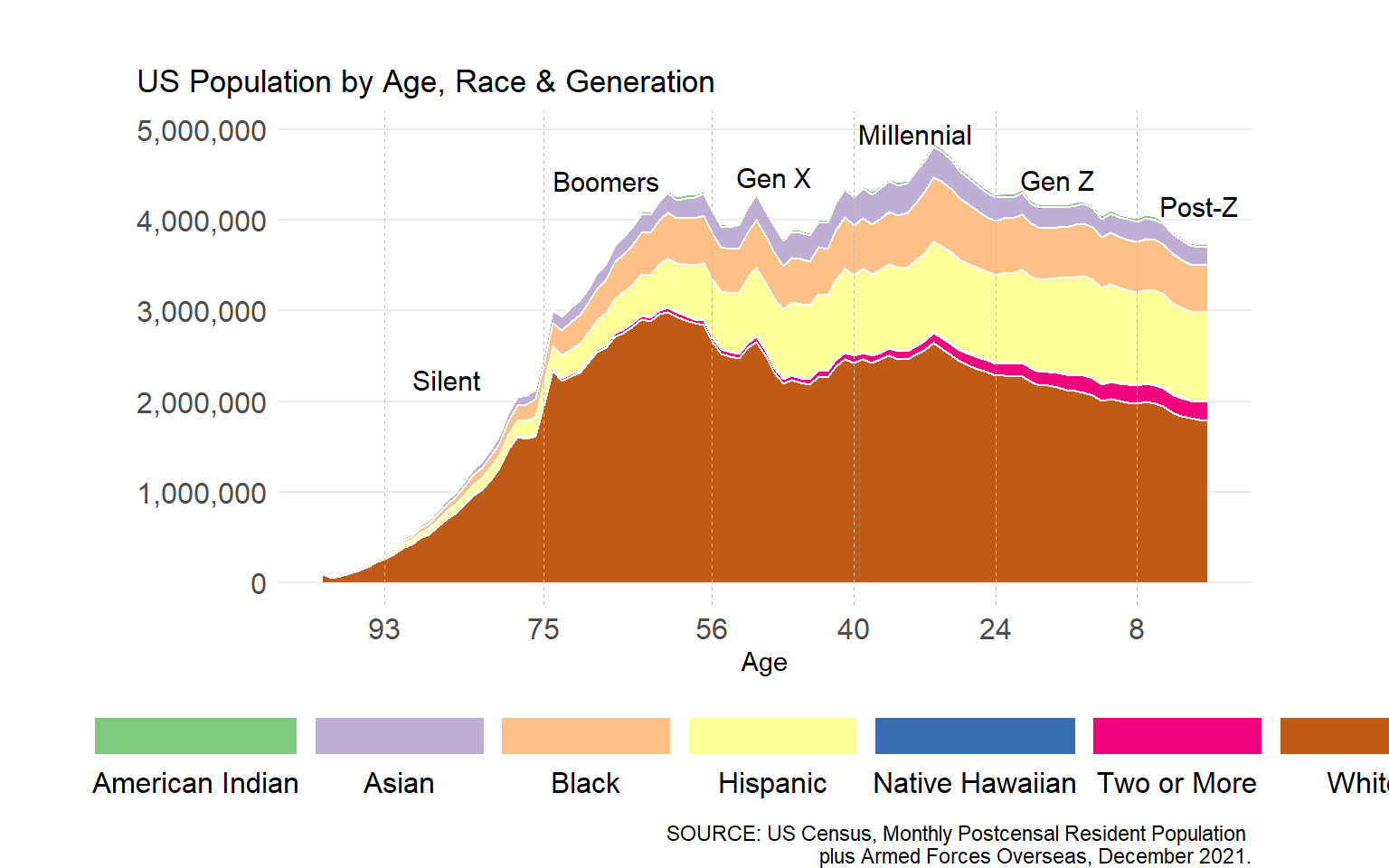
The last figure illustrates a proportional perspective of race & ethnicity in America by single year of age. Per figure, generational differences (at a single point in time) can shed light on (the direction of) potential changes in the overall composition of a given populace, as well as a view of what that populace may have looked like in the past.
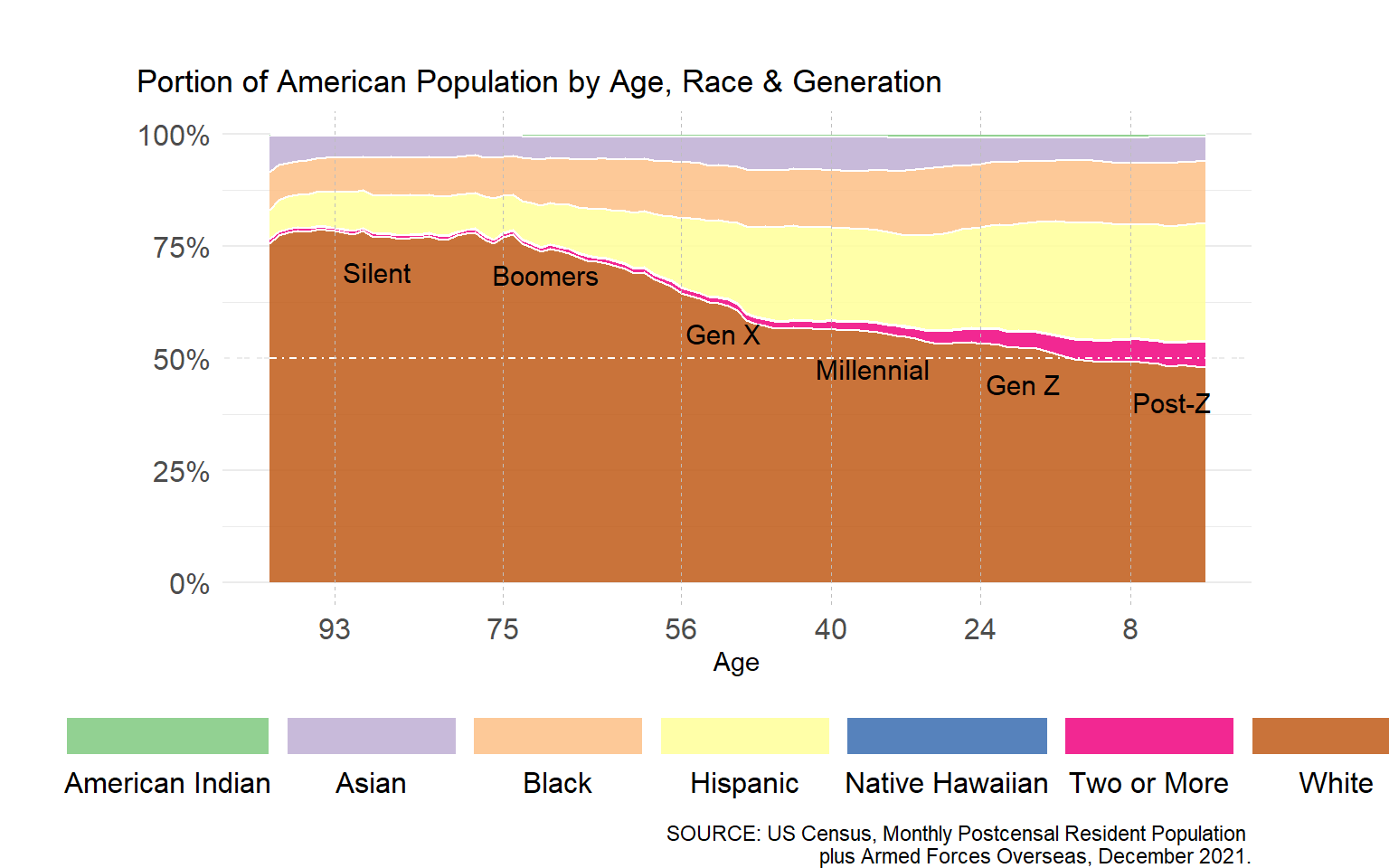
American generations in (apparent) time & space
Aggregate race-ethnicity profiles for America’s seven living generations
are presented in the table below. Per
American Community Survey (ACS)
2020 5-year
estimates,
the Gen X race-ethnicity profile (or distribution) is most
representative of American demographics overall.
| rank | gen | American Indian | Asian | Black | Hispanic | Native Hawaiian | Two or More | White |
|---|---|---|---|---|---|---|---|---|
| 1 | Greatest | 0.4% | 5.7% | 7.7% | 7.3% | 0.1% | 0.8% | 78.0% |
| 2 | Silent | 0.5% | 4.7% | 8.4% | 8.5% | 0.1% | 0.8% | 76.9% |
| 3 | Boomers | 0.7% | 5.0% | 10.9% | 10.9% | 0.1% | 1.0% | 71.4% |
| 4 | Gen X | 0.7% | 6.8% | 12.6% | 18.9% | 0.2% | 1.4% | 59.5% |
| 5 | Millennial | 0.8% | 7.1% | 13.9% | 21.0% | 0.2% | 2.2% | 54.8% |
| 6 | Gen Z | 0.8% | 5.3% | 13.8% | 24.7% | 0.2% | 4.0% | 51.2% |
| 7 | Post-Z | 0.8% | 5.6% | 13.8% | 25.8% | 0.2% | 5.1% | 48.6% |
Race-ethnicity profiles for US Counties
Here, we compare race-ethnicity profiles for US counties to those of
American generations. Using the tidycensus R package, we first obtain
county-level race-ethnicity estimates (ACS 2020 5-year);
then, via the tigris library, we obtain shapefiles for the contiguous
(1) US counties and (2) US states.
Comparing Distributions
The table below highlights the race-ethnicity distribution for my hometown, in Buchanan County, IA, GEOID = 19019.
| Hispanic | White | Black | American Indian | Asian | Two or More |
|---|---|---|---|---|---|
| 1.6% | 95.9% | 0.1% | 0.1% | 0.3% | 1.9% |
Via Kullback–Leibler divergence (ie, relative entropy), we compare the
demographic profile of Buchanan County to the demographic profiles of
each American generation. Per the table below, the Buchanan County
profile is most similar to that of the Greatest generation. Per the
lowest relative entropy value. This is not to say that there are more
Greatest generation in Buchanan County; instead, the racial
demographics of Buchanan County are most akin to an America when the
Greatest generation were in their prime.
| rank | NAME | gen | relative_entropy |
|---|---|---|---|
| 1 | Buchanan County, Iowa | Greatest | 0.1757 |
| 2 | Buchanan County, Iowa | Silent | 0.1872 |
| 3 | Buchanan County, Iowa | Boomers | 0.2493 |
| 4 | Buchanan County, Iowa | Gen X | 0.4079 |
| 5 | Buchanan County, Iowa | Millennial | 0.4762 |
| 6 | Buchanan County, Iowa | Gen Z | 0.5283 |
| 7 | Buchanan County, Iowa | Post-Z | 0.5728 |
At this point, let’s pull the minimum relative entropies for every US County:
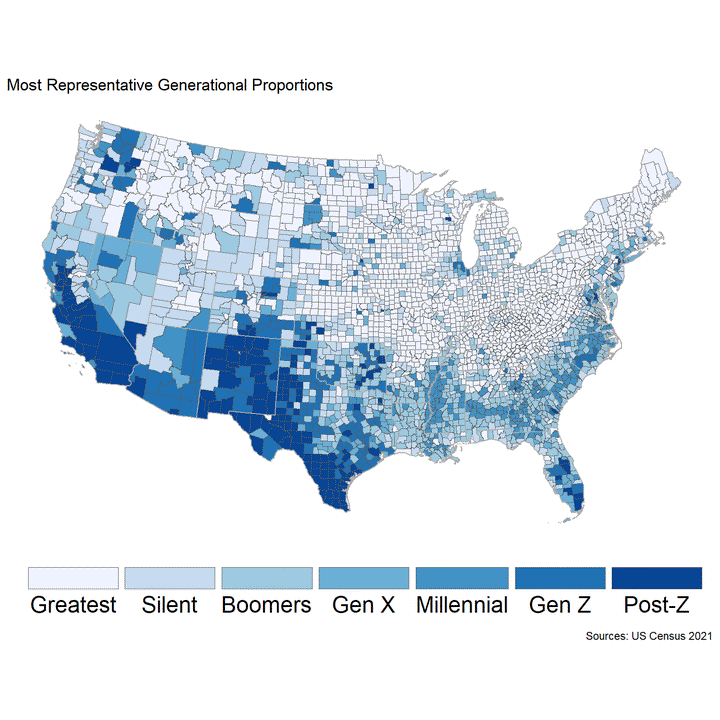
So, while Gen X is most representative of America in the aggregate,
per the map below, the demographics of America’s youngest & eldest
generations are often most prevalent within each county-level unit.
Post-Z in the West, and the Greatest in the East & Midwest. New &
Old Americas, perhaps.
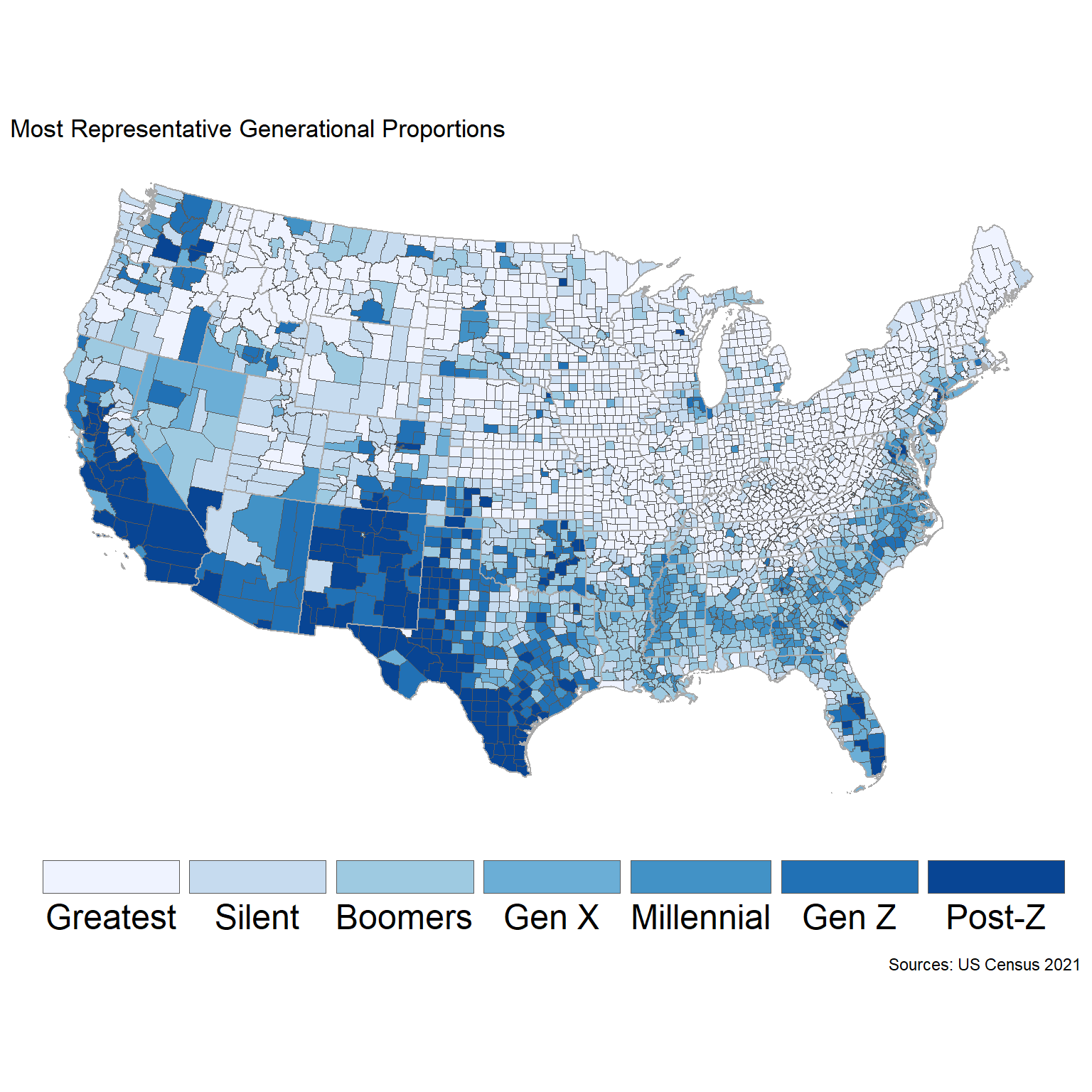
Comparing Grouping Aggregations
Aggregating by county is convenient, but not often the best practice for statistical modeling. In addition to the usual difficulties, models of spatially structured data may have spatial structure in their errors, with different regions being more or less well-described by a given model. This also means that it can be hard to tell how well our model performs when its predictions are aggregated to different scales, which is common when models fit to data from point measurements (for instance, the sale prices of individual homes) are used to try and estimate quantities over an entire area (the average value of all homes in a city or state). If model accuracy is only investigated at individual aggregation scales, such as when accuracy is only assessed for the original point measurements or across the entire study area as a whole, then local differences in accuracy might be “smoothed out” accidentally resulting in an inaccurate picture of model performance.
For this reason, researchers (most notably, Riemann et al. (2010)) have suggested assessing models at multiple scales of spatial aggregation to ensure cross-scale differences in model accuracy are identified and reported. This is not the same thing as tuning a model, where we’re looking to select the best hyperparameters for our final model fit; instead, we want to assess how that final model performs when its predictions are aggregated to multiple scales.
Multi-Scale Assessment
Riemann et al. were working with data from the US Forest Inventory and
Analysis (FIA) program. As a demonstration, we’re going to push a
relative_entropy of the Post-Z generation map through the same
technique. Because our main goal is to show how spatialsample can
support this type of analysis, we won’t spend a ton of time worrying
about feature engineering.
We want to assess our model’s performance at multiple scales, following the approach in Riemann et al, so we need to do the following:
-
Block our study area using multiple sets of regular hexagons of different sizes, and assign our data to the hexagon it falls into within each set.
-
Perform leave-one-block-out cross-validation with each of those sets, fitting our model to
n - 1of thenhexagons we’ve created and assessing it on the hold-out hexagon. -
Calculate model accuracy for each size based on the aggregated predictions for each of those held-out hexes.
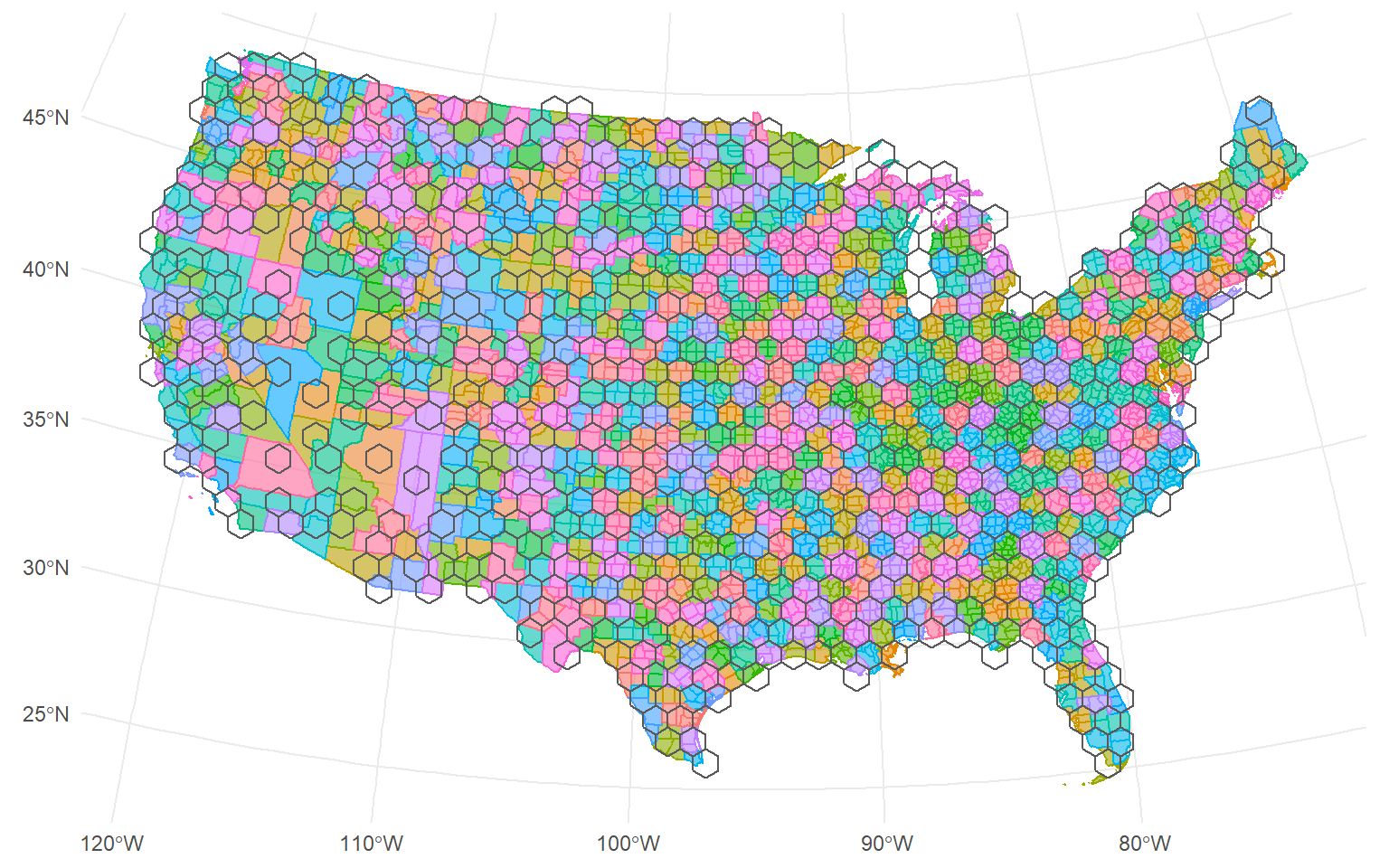
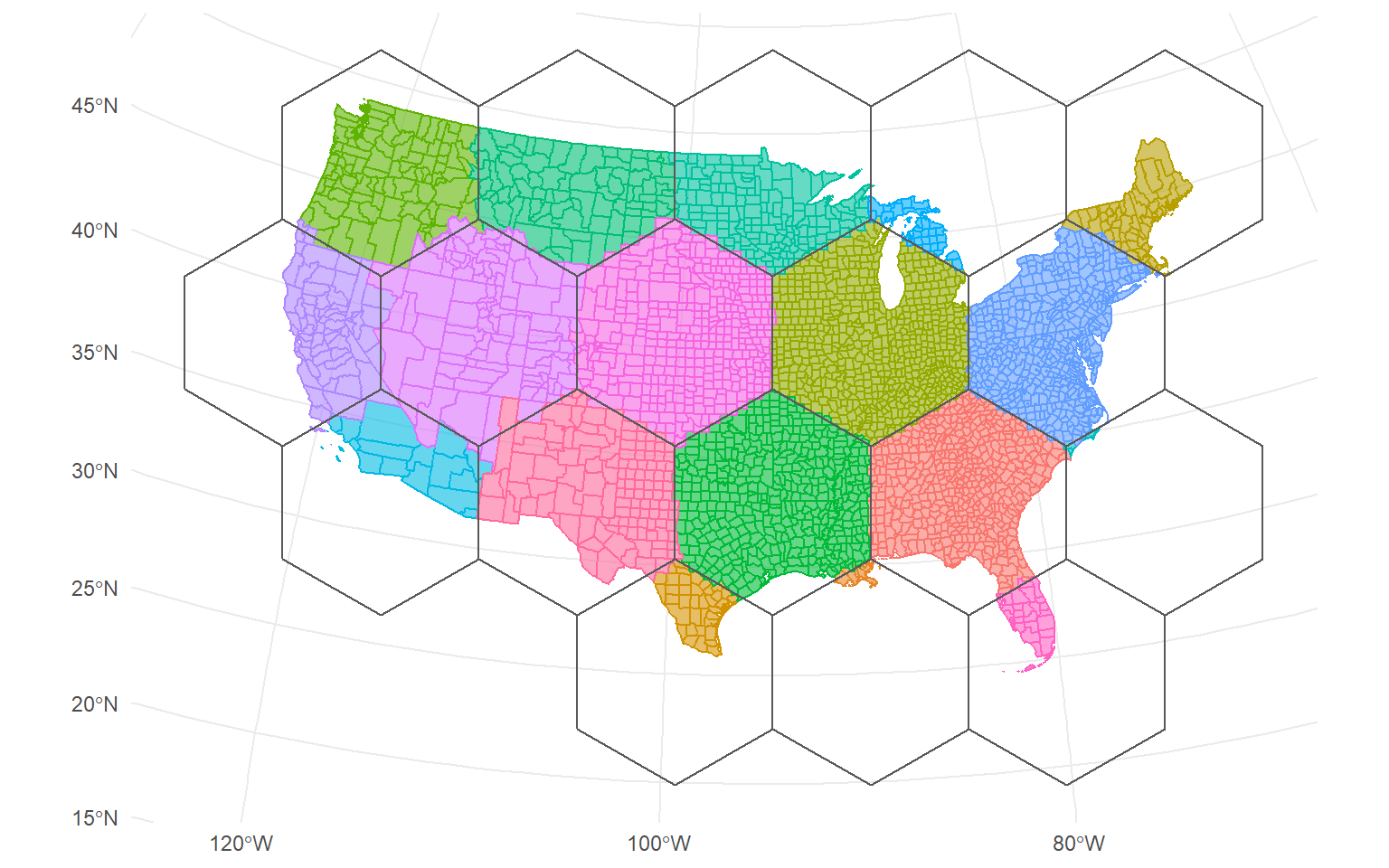
So to get started, we need to block our study area. We can do this using
the spatial_block_cv() function from spatialsample. We’ll generate
ten different sets of hexagon tiles, using cellsize arguments of
between 100,000 and 1,000,000 meters.
Two things to highlight:
cellsize is in meters because our coordinate reference system is in
meters. This argument represents the length of the apothem, from the
center of each polygon to the middle of the side.
v is Inf because we want to perform leave-one-block-out
cross-validation, but we don’t know how many blocks there will be before
they’re created.
If we want, we can visualize a few of our resamples, to get a sense of what our tiling looks like:
And that’s step 1 of the process completed! Now we need to move on to step 2, and actually fit models to each of these resamples. As a heads-up, across all sets of resamples, 1497 is a lot of models, and so is going to take a while:
Here we define a workflow, specifying the formula where we look to understand the relationship between Post-Z relative_entropy with Census demographics on race and model to fit to each resample:
Next, we’ll actually apply that workflow a few thousand times! Now as we
said at the start, we aren’t looking to tune our models using these
resamples. Instead, we’re looking to see how well our point predictions
do at estimating relative entropy across larger areas. As such, we don’t
really care about calculating model metrics for each hexagon, and we’ll
only calculate a single metric (root-mean-squared error, or RMSE) to
save a little bit of time. We’ll also use the control_resamples()
function with save_pred = TRUE to make sure we keep the predictions
we’re making across each resample.
The riemann_resamples object now includes both our original resamples
as well as the predictions generated from each run of the model. We then
“unnest” our predictions and estimate both the average “true”
relative_entropy and our average prediction at each hexagon:
# A tibble: 6 x 3
cellsize mean_relative_entropy mean_pred
<dbl> <dbl> <dbl>
1 100000 0.462 0.422
2 100000 0.852 0.482
3 100000 0.467 0.417
4 100000 0.888 0.232
5 100000 0.483 0.462
6 100000 1.69 1.72
Now that we’ve got our “true” and estimated relative_entropy for each
hexagon, all that’s left is for us to calculate our model accuracy
metrics for each aggregation scale we investigated. We can use functions
from yardstick to quickly calculate our root-mean-squared error (RMSE)
and mean absolute error (MAE) for each cell size we investigated:
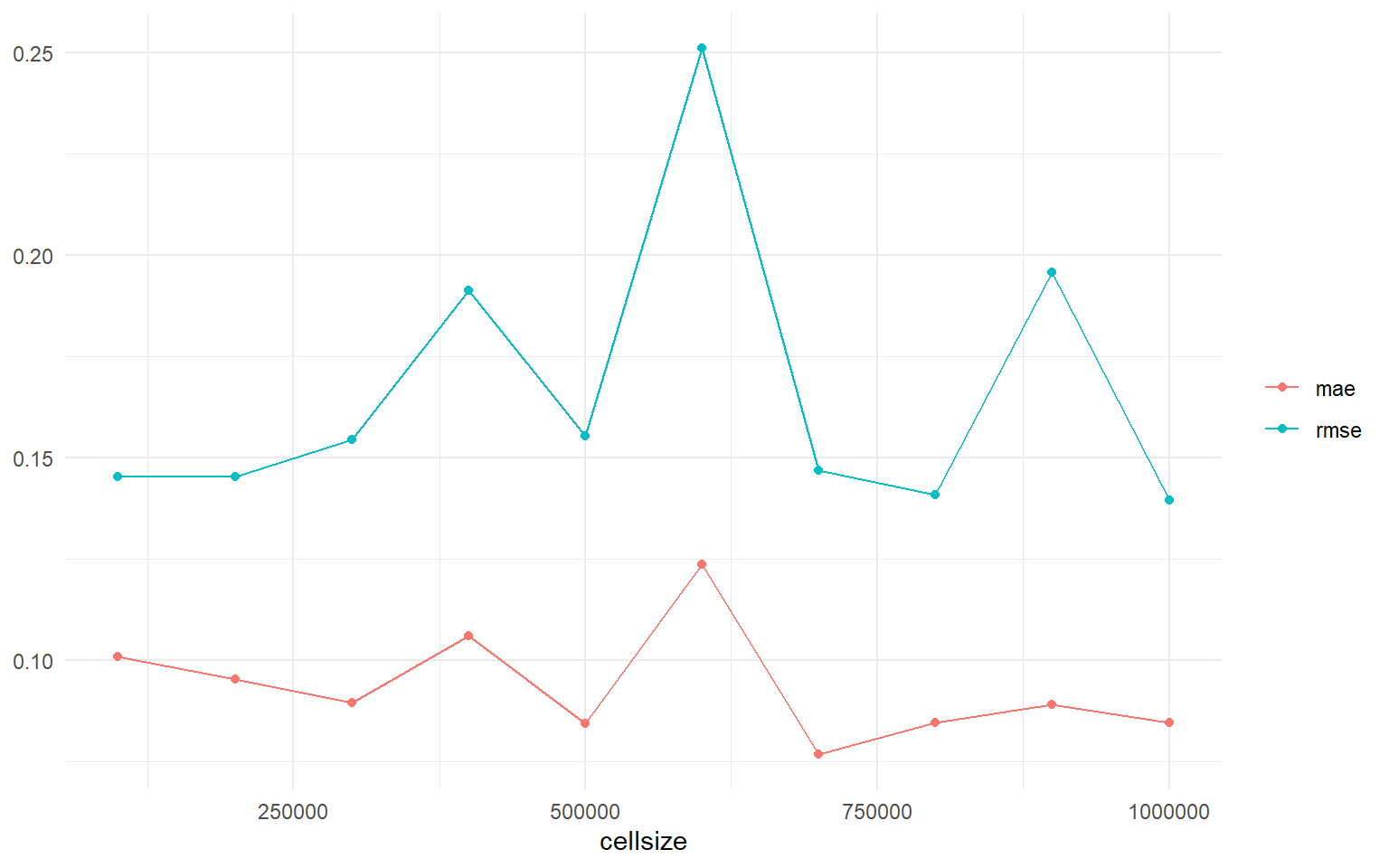
And just like that, we’ve got a multi-scale assessment of our model’s accuracy. To repeat a point from earlier, we aren’t using this as a way to tune our model. Instead, we can use our results to investigate and report how well our model does at different levels of aggregation. For instance, while it appears that both RMSE and MAE improve as we aggregate our predictions to various size hexagons, some scales have a larger difference between the two metrics than others. This hints that, at those specific scales, a few individual hexagons are large outliers driving RMSE higher, which might indicate that our model isn’t performing well in a few specific locations:
Conclusion
There are many ways to characterize the different perspectives on the composition of America & American generations, and the changing demographics of America.
References
Riemann, R., Wilston, B. T., Lister, A., and Parks, S. 2010. An effective assessment protocol for continuous geospatial datasets of forest characteristics using USFS Forest Inventory and Analysis (FIA) data. Remote Sensing of Environment, 114, pp. 2337-2353. doi: 10.1016/j.rse.2010.05.010.